Building a Lambda function to process a CSV when uploaded to an S3 bucket
Journey: 📊 Community Builder 📊
Subject matter: Building on AWS
Task: Building a Lambda function to process a CSV when uploaded to an S3 bucket.
This project is about serverless automation.
Using the 6 Pillars of the AWS Well-Architected Framework, Performance Efficiency will be achieved in this build.
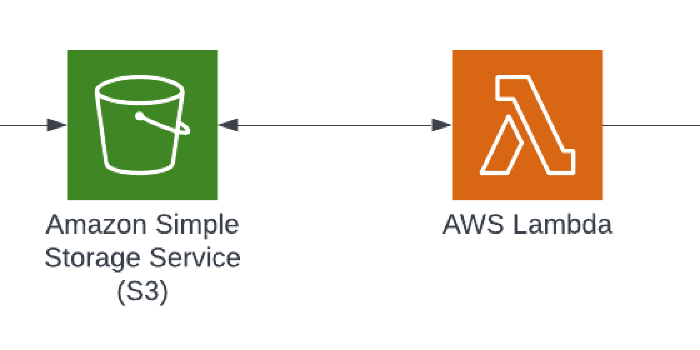
I will be setting up a Lambda function which triggers automatically whenever a CSV file is uploaded to an Amazon S3 bucket. The Lambda function reads the CSV file, calculates an average of the contents and then prints the calculation to a Cloudwatch log.

Credit: This serverless architecture was created using guidance from Arsh on Medium Here
What did I use to build this environment?
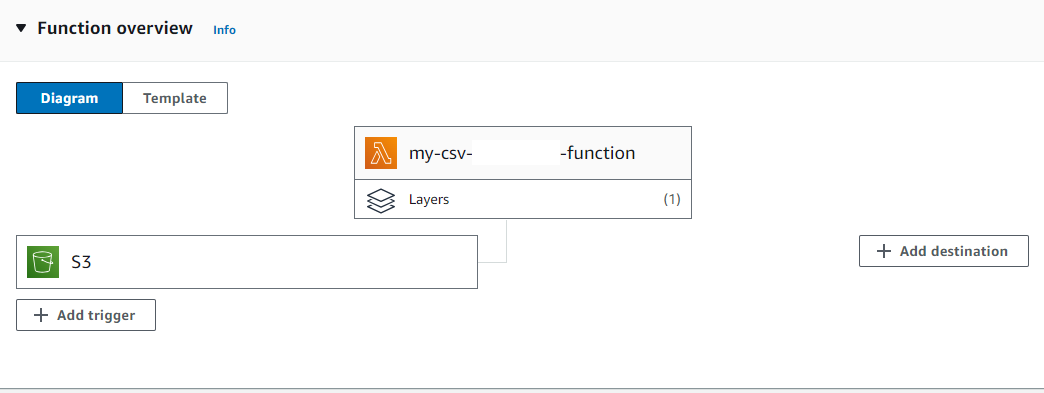
- AWS Lambda [with Panda layers]
- Amazon S3
- Amazon Cloudwatch
- AWS Management Console
- IAM
What is built?
- A new S3 bucket
- A configured, layered Lambda function using Python
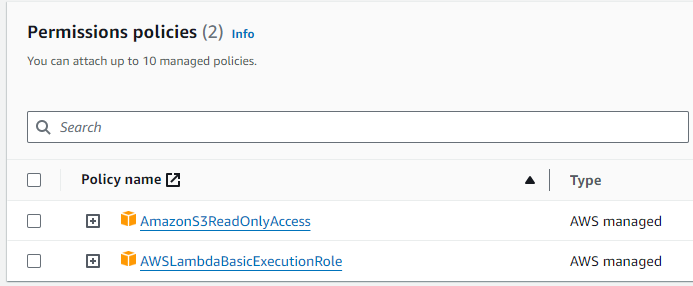
Using the principle of least privilege:
Taken from the AWS documentation Here:
“The principle of least privilege states that identities should only be permitted to perform the smallest set of actions necessary to fulfill a specific task.”
To obtain the correct Lambda Permission for this, I used some further documentation Here
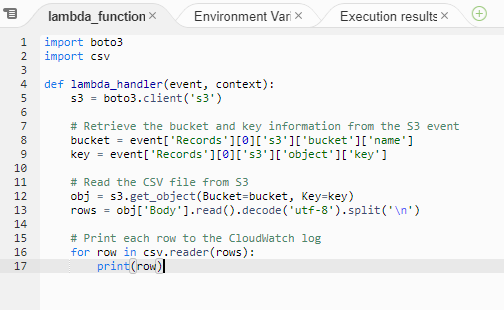
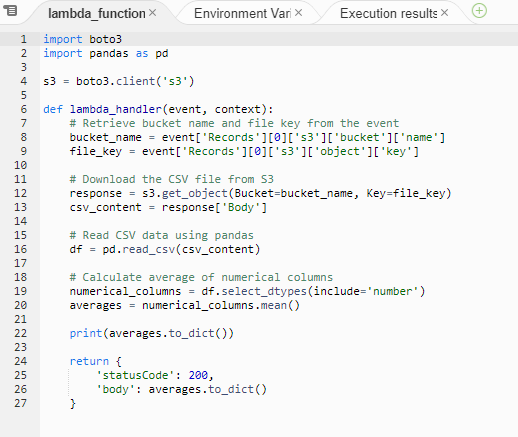
This task involved using initial Python code to import and print the CSV file contents. Once this was working, I then amended the Python code to generate an average score against the CSV dataset.
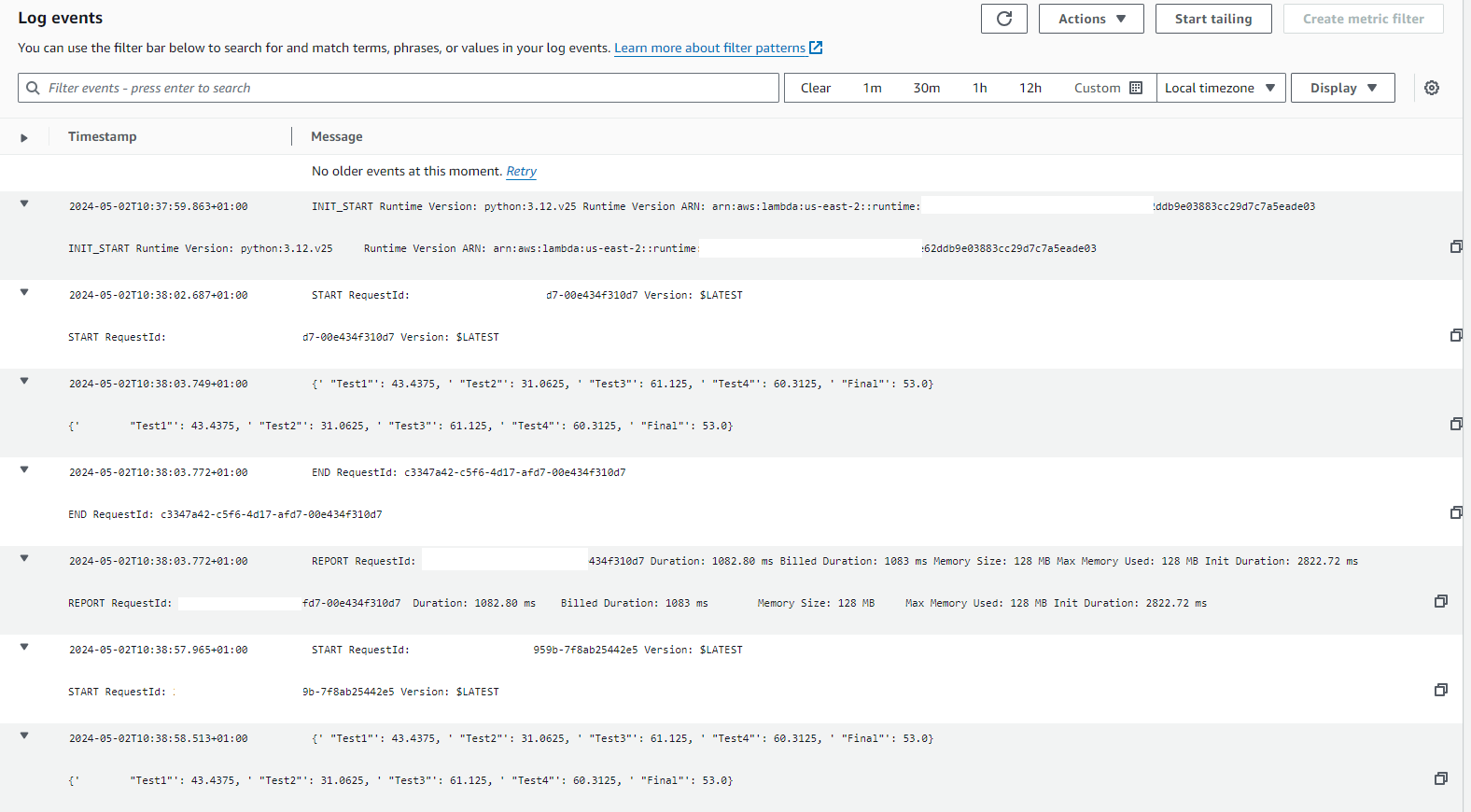
Once I had configured all of the areas, the Lambda function successfully calculated the average and printed it to the Cloudwatch logs.
Some of the highlights…
IAM Lambda Role Permissions:
Lambda function:
Initial Lambda code:
Initial Lambda test:
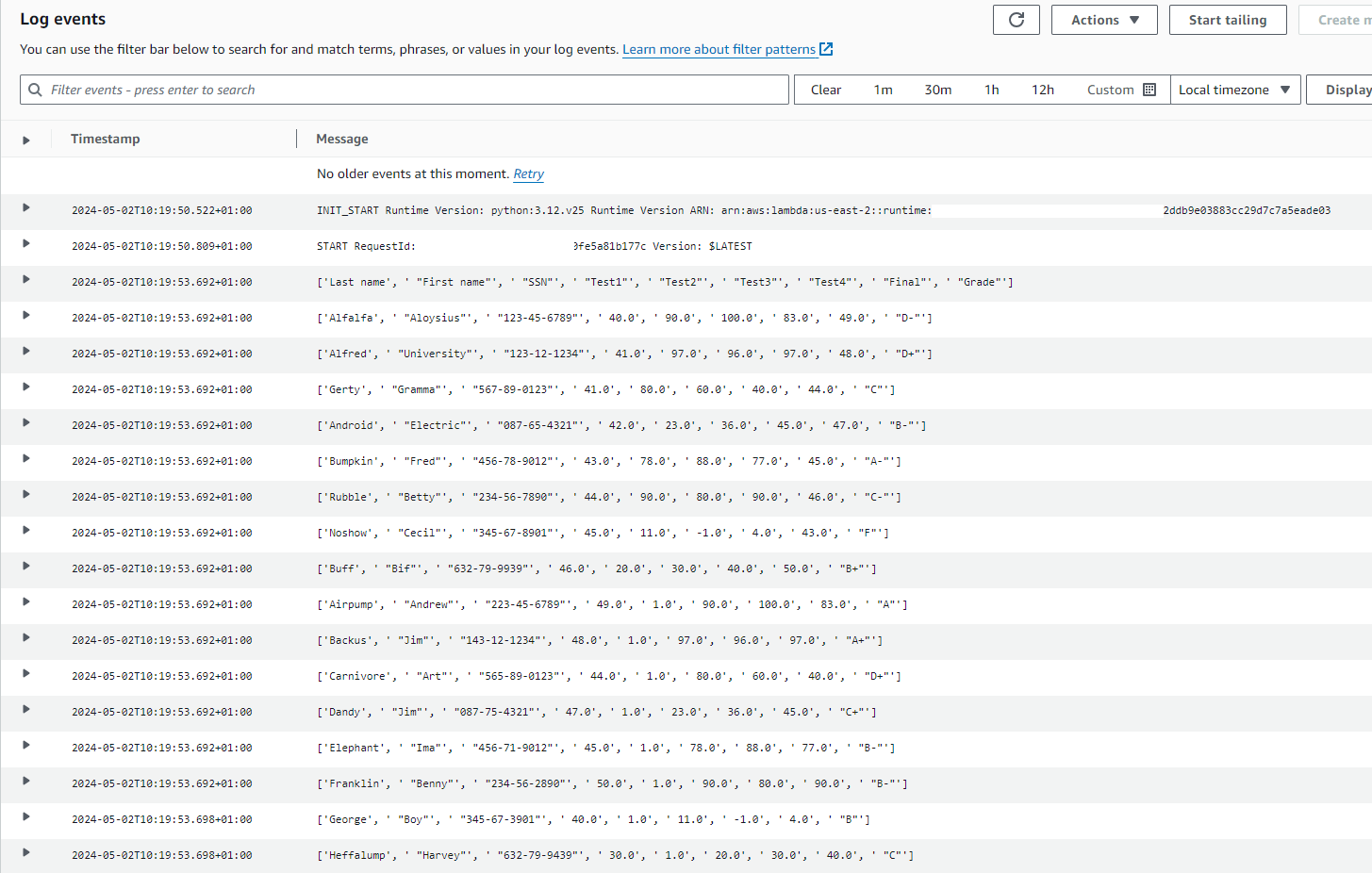
Cloudwatch output:
Enhanced Lambda code:
Lambda layer:

New Cloudwatch output:
My interpretation of the architecture:

I hope you have enjoyed the article, I enjoyed the build!
