Building a Data Lake, ingesting and analysing data!
Journey: 📊 Community Builder 📊
Subject matter: Building on AWS
Task: Building a Data Lake, ingesting and analysing data!
This project is about Scalability in data analysis.
Using the 6 Pillars of the AWS Well-Architected Framework, Performance Efficiency and Sustainability will be achieved in this build.
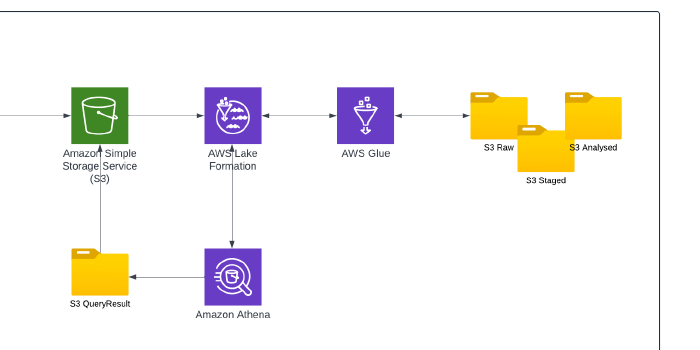
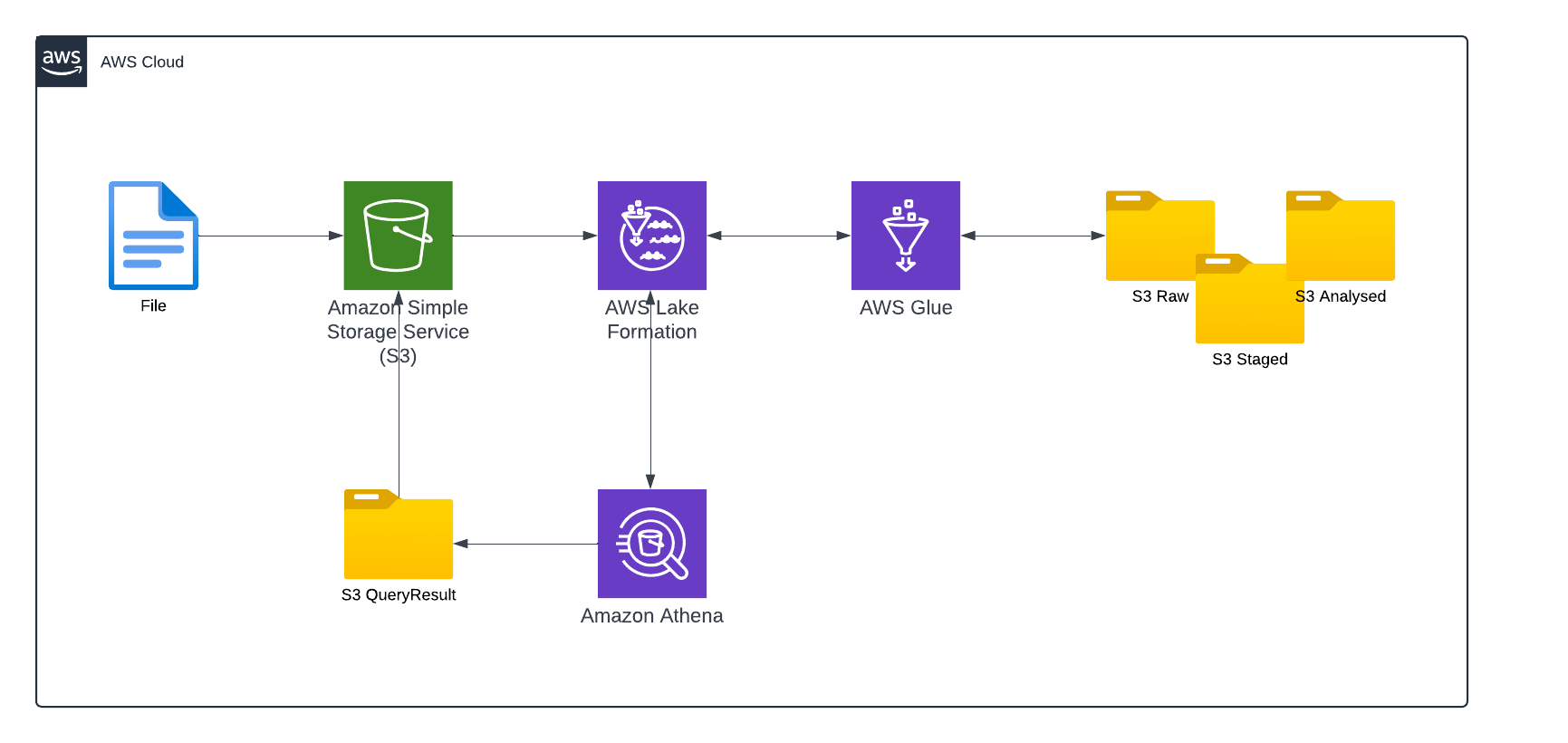
Today, I will be building a Data Lake. I will be using raw data held in a CSV file, hosted in an S3 bucket which will be ingested into the Data Lake using a Glue Crawler. This will create a table in Lake Formation that contains the schema information which can then be read. Finally, I will use the serverless query engine Amazon Athena to query the dataset.

Resource credit: This serverless architecture was created using guidance from Haimo Zhang on Medium Here.
What did I use to build this environment?
- Amazon S3
- AWS Lake Formation
- AWS Glue
- Amazon Athena
- AWS IAM
What is built?
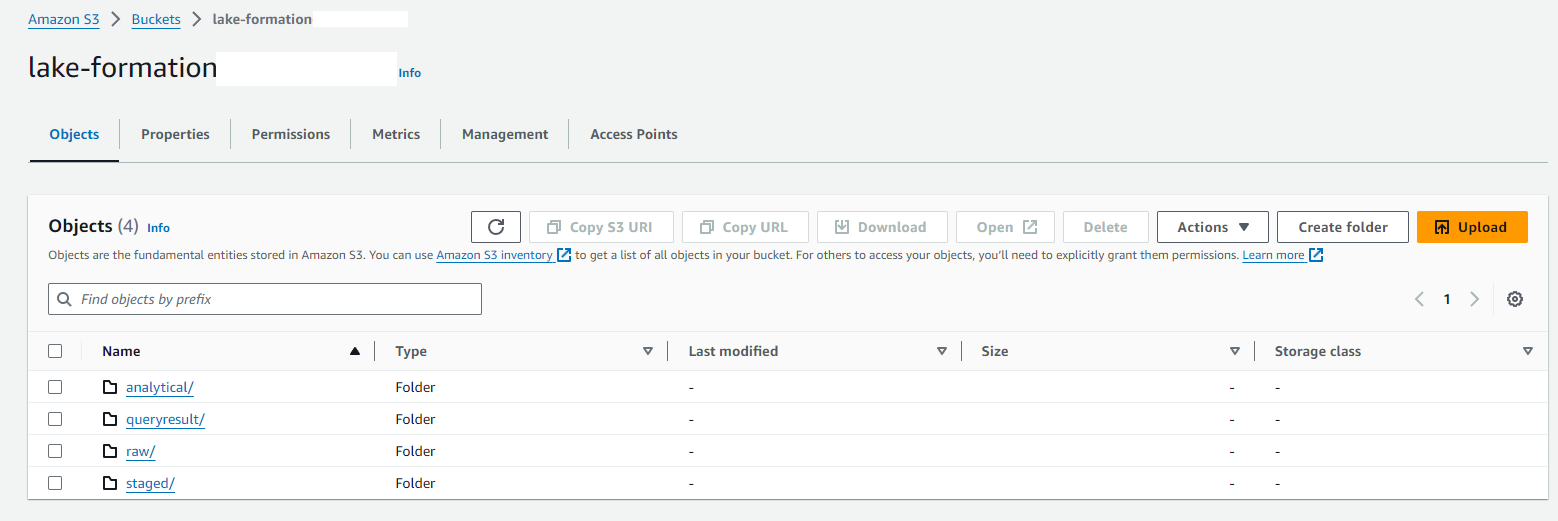
- A new S3 bucket with data capture and processing folders
- A new Lake Formation database, configured to house ingested data in a database table.
- A Glue Crawler, created in AWS Glue to discover and create a schema for Athena to be able to query the dataset.
- Amazon Athena is configured to point to the ingest table and export data to a QueryResult folder in the S3 bucket.
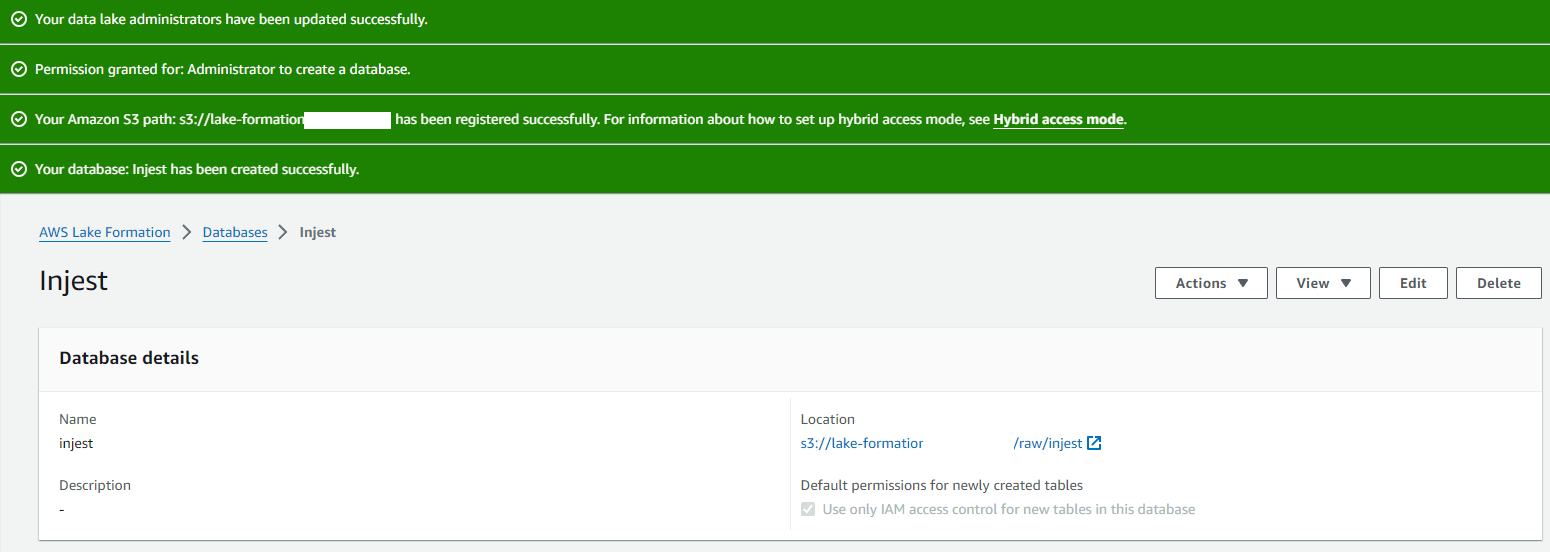
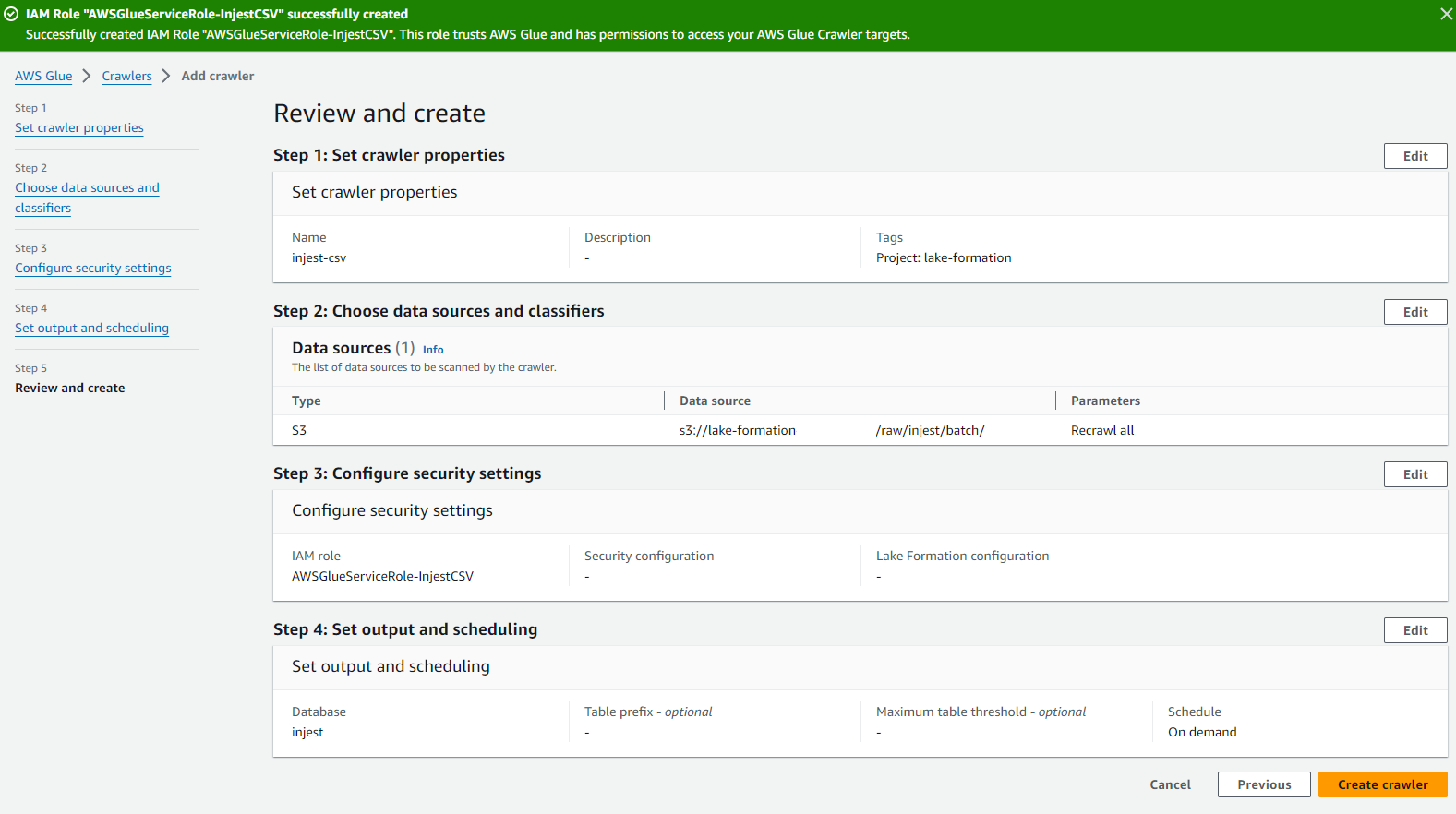
In this task, I created a new S3 bucket and created analytics sub-folders to house the various stages of analysed data. I then registered the location of my S3 bucket in Lake Formation and assigned an IAM role to perform the tasks. After creating a new database to ingest the data, I created a Glue Crawler in AWS Glue. I pointed the Crawler at my raw sample CSV dataset and assigned the IAM role. After granting the Crawler access to the Lake Formation Database, I was then able to run the Crawler service which took roughly 1 minute to process.
When I returned to AWS Lake Formation, I observed that AWS Glue had successfully created a batch table in the database which contained schema information and data.
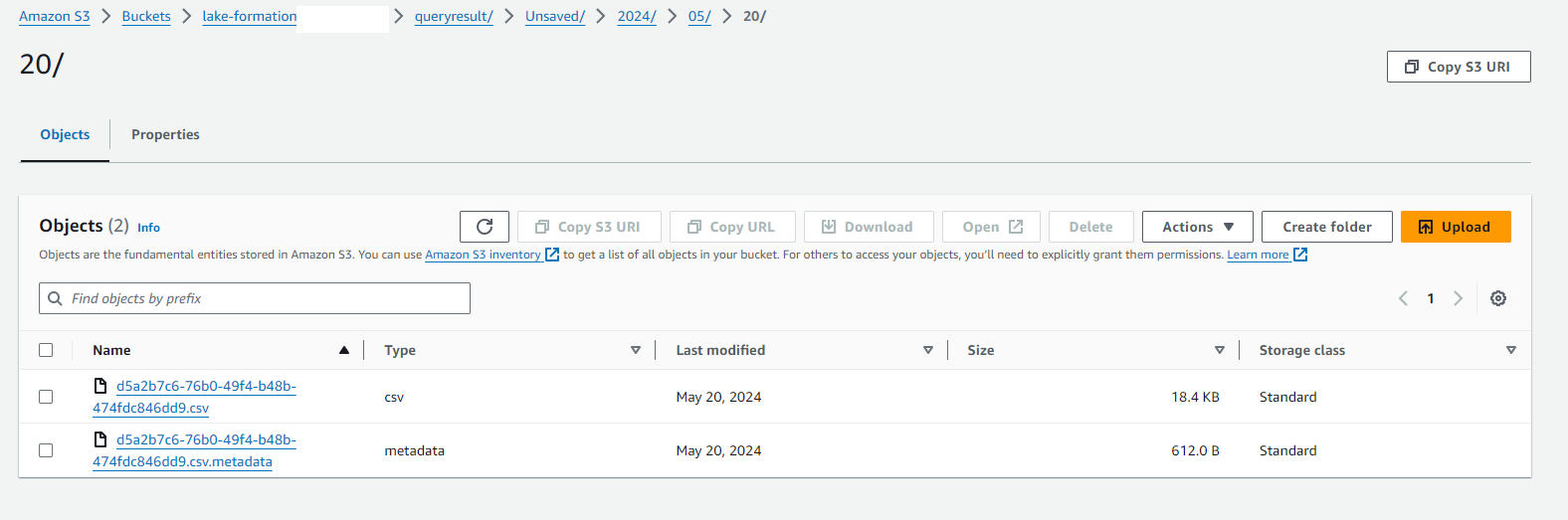
This permitted me to use Amazon Athena to query the data. I first had to create a location to output the query data that Athena was analysing. I used a new folder in my S3 bucket for this. Once I pointed Athena to the ingest table and ran a general query to return all rows as a test, it successfully output the data in the query results pane and also printed the output to my S3 bucket!
I also used the following AWS documentation to troubleshoot database creation in Lake Formation:
https://docs.aws.amazon.com/healthlake/latest/devguide/troubleshooting-data-lake-admin.html
I have performed labs in AWS Cloud Quest previously under the Data Analytics role where I used Data Lakes, Glue and Athena, but I had never set it up from scratch before. I enjoyed seeing how it all came together. Being able to run a query against data that has just been ingested from raw data was quite satisfying as I could watch one process passing off to the other in real time.
Some of the highlights…
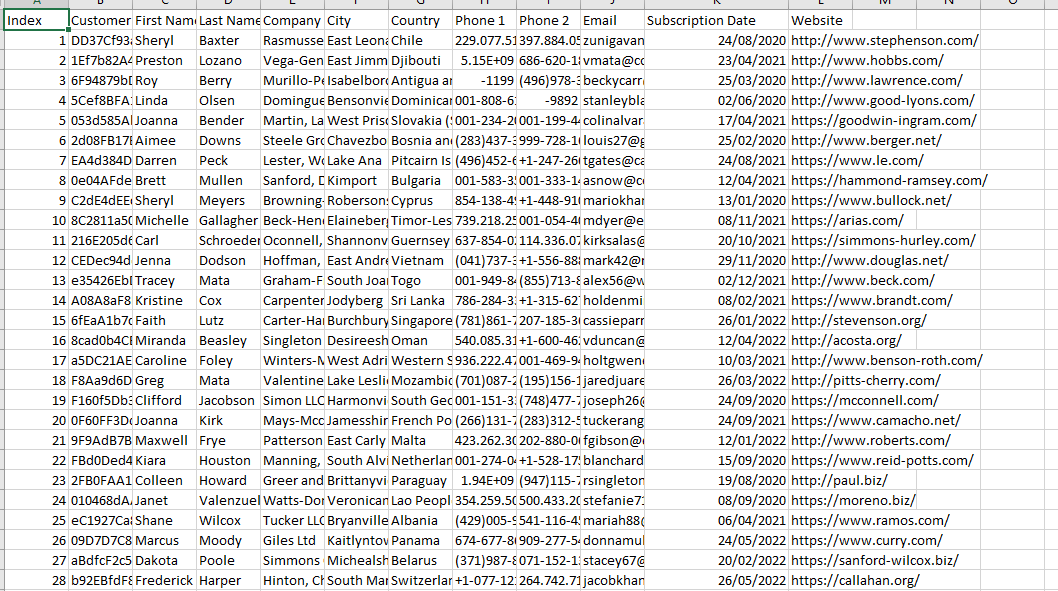
Raw CSV sample data:
Amazon S3:
AWS Lake Formation database creation:
Glue Crawler creation:
Crawler run:
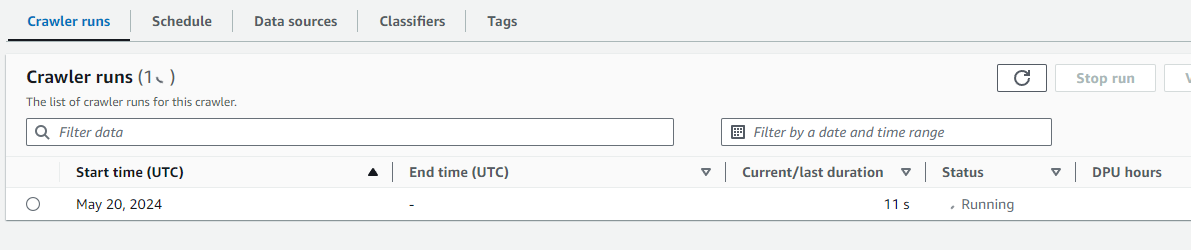
Crawler complete:

AWS Lake Formation schema information data table:

Athena querying the data:
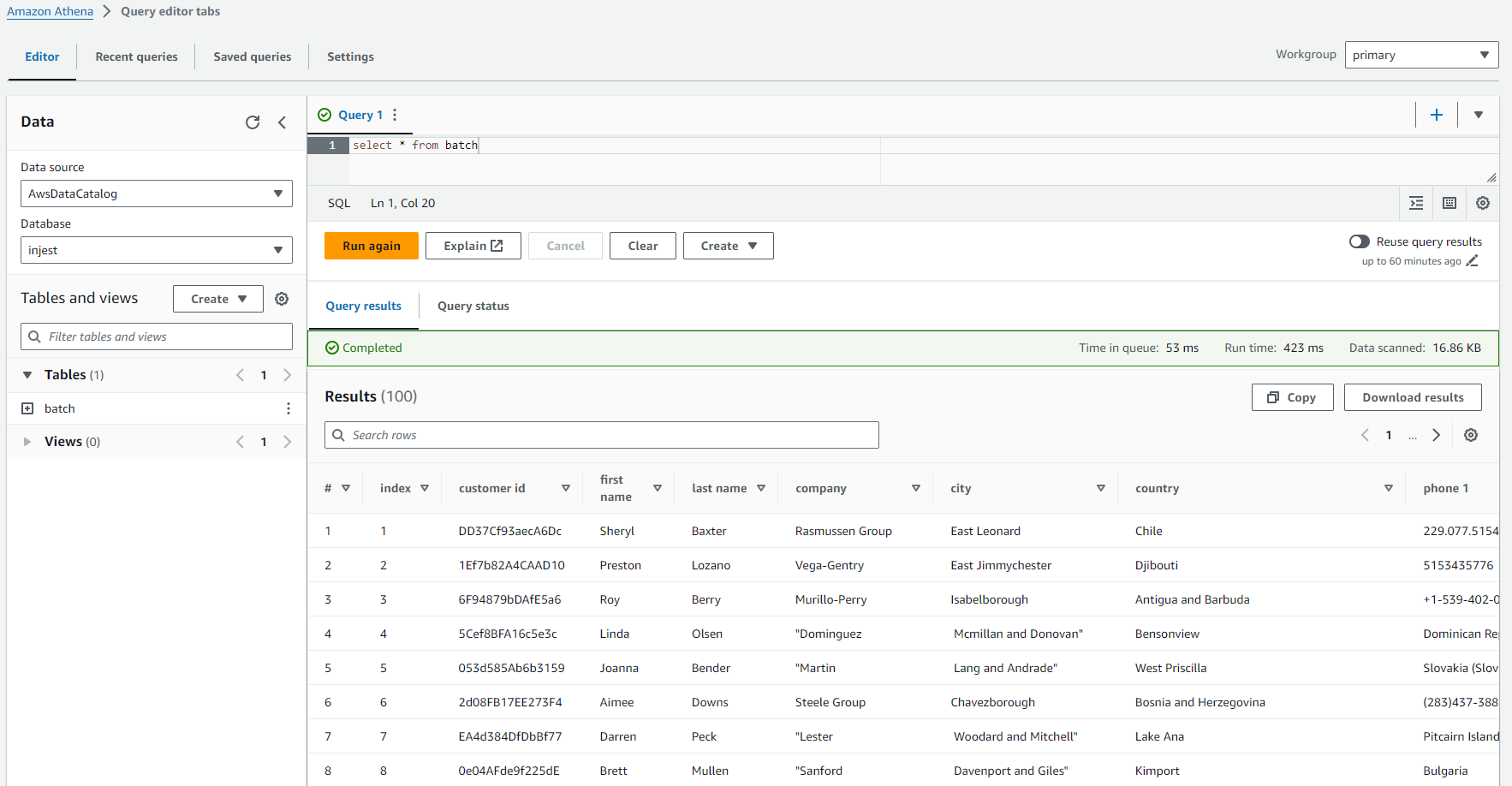
Athena returning data in the S3 bucket:
My interpretation of the architecture:
I hope you have enjoyed the article!
